La programmation n'est pas que de la pure bidouille, il y a une théorie derrière... C'est pour cela que je vous propose ce mois-ci de découvrir comment mesurer l'efficacité - la complexité temporelle - d'un algorithme. Vous pourrez avoir un exposé plus précis de ceci dans un cours d'informatique de premier ou second cycle universitaire (ou de classe prépa).
En fait, il faudrait distinguer deux types de complexité : la complexité temporelle et la complexité spatiale. La complexité temporelle permet d' évaluer quel va être la rapidité d'exécution d'un algorithme en fonction d'un ou de plusieurs paramètres dépendant de la ou des données en entrée. La complexité spatiale - vous l'aurez compris - permet d'évaluer l'occupation mémoire que va nécessiter un algorithme en fonction (toujours) de certains paramètres. Mais je ne vous apprendrais rien en vous disant que de nos jours la mémoire n'est plus un paramètre réellement limitant, le prix de la RAM ayant énormément baissé en une vingtaine d'années (de plus la mémoire virtuelle est une autre réponse à ce problème).
Ainsi, nous allons mesurer la complexité temporelle d'un algorithme. Pour y parvenir, nous devons déjà voir quelle 'unité' choisir... Prendre la seconde comme unité n'est pas un bon choix : en effet, la vitesse des microprocesseurs ne cesse d'évoluer et une instruction qui prendrait énormément de temps aujourd'hui risquerait de n'en prendre que très peu dans un futur proche. Ainsi, nous allons plutot étudier la complexité d'un algorithme en choisissant généralement l'instruction la plus coûteuse et en évaluant le nombre de fois qu'elle est exécutée en fonction d'un ou de plusieurs paramètres dépendant des données en entrée : la longueur n d'une liste, la hauteur n d'un arbre, l'indice n lorsque qu'il s'agit de calculer le n-ème terme d'une suite, ... Il est possible d'utiliser plus d'un seul paramètre ; par exemple, pour une fonction faisant l'union de deux arbres a et b , la complexité dépendra de la hauteur |a| de l'arbre a et de la hauteur |b| de l'arbre b. L'instruction la plus coûteuse est la comparaison de deux objets lors d'un algorithme de tri, les opérations arithmétiques + et * lors d'un algorithme de multiplication de polynomes ou de matrices, ...
Enfin, il nous faut une échelle de comparaison et c'est là que l'outil mathématique intervient :
La propriété suivante est bien pratique :
na=O(nb) si et seulement si a<=b
On a aussi le résultat (qui permet de simplifier des calculs) :
si f=O(g) et g>=0 alors S(f(k),k=1..n)=O(S(g(k),k=1..n)) où S(u(k),k=1..n)=u(1)+...+u(n)
si f=O(g) on dit aussi que f est dominée par g. Cette relation de domination est réflexive et transitive. C'est-à-dire :
mais n'est pas symétrique :
soit a<b, alors na est dominée par nb mais nb n'est pas dominée par na
Ainsi, avec un grand O, on sait à quoi s'attendre dans le pire des cas alors qu'avec un grand thêta, on sait à quoi s'attendre tout le temps. En général, on utilise surtout le grand O...
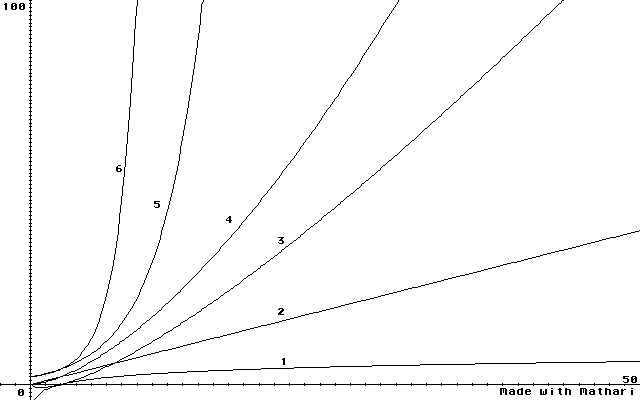
On peut alors classifier les complexités :
Voici quelques exemples de calculs simples de complexité :
Soit la fonction récursive suivante en GFA-Basic :
FUNCTION factorielle(n%)
IF n%=0 OR n%=1
RETURN 1
ELSE
RETURN n%*factorielle(n%-1)
ENDIF
ENDFUNC
nous allons mesurer la complexité de cette fonction en comptant le nombre d'exécutions de "l'instruction" (l'opération) *.
Soit n l'entier dont on veut calculer la factorielle et T(n) le nombre d'opérations * que nécessite le calcul de n! .
On a : T(0)=T(1)=0
pour calculer n!, on calcule (n-1)! et on multiplie
par n, d'où
T(n)=1+T(n-1)
finalement, on peut expliciter T(n) pour tout
n :
on a évidemment T(n)=n-1 pour
n>0, T(0)=0
or n-1=O(n) donc
T(n)=O(n), la complexité
de cet algorithme est donc en O(n) :
complexité linéaire.
' On suppose que la tableau a%() est un tableau global d'entiers
' de longueur n&
' La procédure echange se charge d'échanger deux éléments de a%()
' d'indice i& et j&
PROCEDURE echange(i&,j&)
LOCAL tmp%
tmp%=a%(i&)
a%(i&)=a%(j&)
a%(j&)=tmp%
RETURN
' Le tri par sélection
PROCEDURE tri_selection(n&)
LOCAL mini&,i&,j&
mini&=0
FOR i&=0 TO n&-2
mini&=i&
FOR j&=i&+1 TO n&-1
IF a%(j&)<a%(mini&)
mini&=j&
ENDIF
NEXT j&
echange(i&,mini&)
NEXT i&
RETURN
plus haut dans le texte, nous avons vu que pour un tri, on
choisissait comme opération la plus coûteuse la
comparaison, on peut choisir aussi le nombre
d'échanges. Nous allons donc successivement
déterminer la complexité du tri par
sélection en comparaisons et en échanges.
Voilà pour cette courte intrusion dans la théorie... La prochaine fois, je parlerais exclusivement de programmation mais je ne sais pas encore à quel sujet. D'ici là, portez-vous bien et essayez d'évaluer la complexité de vos algorithmes afin, éventuellement, de vous rendre compte qu'un petit changement de point de vue (donc d'algorithme) est bougrement nécessaire... ;-)
auteur : Seb/the Removers
[Entrée du site] [Presentation du groupe] [Nos articles] [Nos logiciels] [Téléchargement] [Nos liens] [Contacts] [Nouveautés du site]
[Main page] [Presentation of the group] [Our products] [Download] [Links] [Contacts] [What's new]
